Véleményünk szerint három különböző megközelítést érdemes mérlegelni, ha olyan megoldást keresünk, amely segít feldolgozni a strukturálatlan dokumentumokat:
- Felhőalapú dokumentumfeldolgozó szolgáltatások
- Saját fejlesztésű nagy nyelvi modellek (LLM-ek)
- Nyílt forráskódú nagy nyelvi modellek (LLM-ek)
Felhőalapú dokumentumfeldolgozó szolgáltatások
A felhőszolgáltatók régebb óra kínálnak speciális szolgáltatásokat dokumentumokból történő adatkinyerésre:
- AWS (Textract)
- Azure (AI Document Intelligence)
- Google (Document AI)
Ezek a megoldások hasonlóak, számos funkciót tartalmaznak, mint például OCR, táblázatkinyerés, szűrők stb. és sokféle dokumentumformátumot támogatnak alapértelmezés szerint. A használatukhoz API-kon keresztül integrálhatók a rendszerbe, így a forrásdokumentumokat a felhőbe kell elküldeni.
Előnyök:
- Könnyű az indulás
- Pontosság
- Skálázhatóság
- Nincs szükség helyi szerver infrastruktúrára
Hátrányok:
- Szolgáltatófüggőség (vendor lock-in)
- Korlátozott rugalmasság
- Adatvédelmi aggályok
Saját fejlesztésű nagy nyelvi modellek (LLM-ek)
A legismertebb AI szolgáltatók API-n keresztül kínálják nagy nyelvi modelljeiket. Ennél a megközelítésnél a feldolgozandó dokumentumot előkészítve az API-n keresztül kell elküldeni, a feldolgozás pedig a szolgáltató infrastruktúrájában történik.
Saját fejlesztésű LLM-ek:
- OpenAI GPT
- Anthropic Claude
- Google Gemini
- Mistral AI
Mi az OpenAI-t ajánljuk, mivel a piacon jelenleg ez a legkorszerűbb megoldás. Az OpenAI a Microsoft Azure adatközpontjait használja, és lehetőség van adatmegőrzés nélküli üzemmódot választani, valamint kérhető az EU-s adatközpont használata is.
Előnyök:
- Rugalmasság
- Jobb kontextusértés
- Gyors modellfejlesztés
- Multimodális (szöveg és kép bemenettel is működik)
- További funkciók megvalósíthatók, például ügyfélszolgálati chatbot
- Nincs szükség helyi szerver infrastruktúrára
Hátrányok:
- Adatvédelmi aggályok
- Szolgáltatófüggőség (bár az OpenAI API-ját sok más LLM is használja)
- Fekete dobozként működik (belső működés nem átlátható)
Nyílt forráskódú nagy nyelvi modellek (LLM-ek)
A nyílt forrású nagy nyelvi modellek generatív AI megoldások, amelyek helyben telepíthetők és taníthatók. Az alapmodell átfogó előzetes képzéssel rendelkezik, amely lehetővé teszi kontextusértést, emellett a modellt specifikus területekre is tovább lehet tanítani.
Nyílt forrású/súlyozott LLM-ek:
- Meta Llama
- Google Gemma
Ajánljuk a Meta Llama modellt, amely gyorsan fejlődik és multimodális képességekkel is rendelkezik (például a Llama3.2 képek feldolgozására is képes).
Előnyök:
- Nincsenek adatvédelmi aggályok, a dokumentumok nem hagyják el a saját infrastruktúrát
- Nincs szolgáltatófüggőség
- Egyedi megoldás (hosszú távon a modell képzésével)
- Kódátláthatóság
- Teljes kontroll
Hátrányok:
- Magasabb kezdeti költségek, mivel helyi szerver infrastruktúrára van szükség
- Pontosság a modell méretétől függ; nagyobb modellhez komoly szerver teljesítmény kell
- Skálázhatóság
- Szerver kihasználtság nem optimális
Összegzés
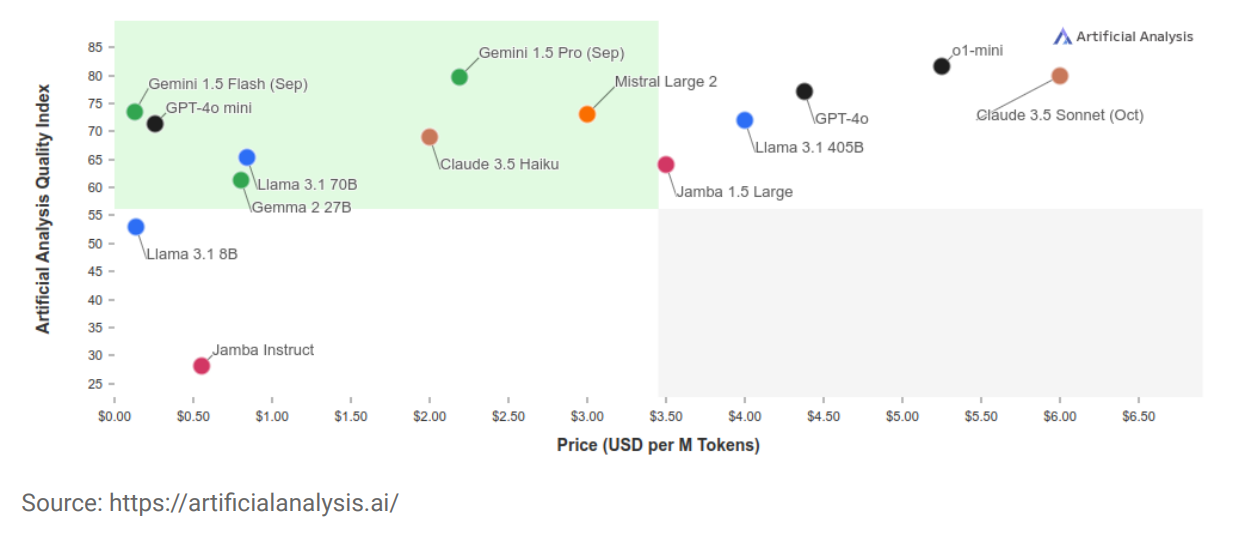
Nehéz előre megjósolni egy AI modell teljesítményét egy adott feladatra. Egyrészt a modellek rendkívül összetettek és nem-determinisztikusak, másrészt a bemeneti PDF dokumentumok heterogének: gyakran be vannak szkennelve, illetve eltérő a formázásuk is. Figyelembe kell venni, hogy ez egy gyorsan változó terület, ezért nem érdemes egyetlen szállítóhoz vagy megoldáshoz elköteleződni.
Törekedni kell arra, hogy a nyelvi modell könnyen cserélhető legyen, így az új verziók vagy fejlettebb modellek előnyei könnyebben kihasználhatók lesznek, és csökkenthető a szállítófüggőség.
Szerző:
Kenéz András
Fejlesztési vezető, szoftverarchitekt
2024.12.05.